Technical Evidence¶
Reviewer evidence
Technical evidence without the wall of links¶
This page is the short version. It is designed for a reviewer who wants to know what was actually built without being dropped into every ADR, API reference and deployment note at once.
Use it as a map: start with the summary, choose one review path, and open the deep dive only if you want the full technical archive.
Production Incidents¶
Serving concurrency
81% API errors -> 0%¶
Symptom: Locust exposed an 81% error rate under concurrent prediction traffic.
Hypothesis: it first looked like a scaling or CPU allocation problem.
Diagnosis: uvicorn --workers N under
Kubernetes created contention inside a shared pod CPU budget, while synchronous
ML inference blocked the FastAPI event loop.
Fix: one worker per pod, Kubernetes HPA for horizontal
scaling, and CPU-bound inference moved to
asyncio.run_in_executor() with ThreadPoolExecutor.
Result: error rate dropped to 0% in validation and the CPU request was reduced by roughly 50%.
Explainability
All-zero SHAP outputs¶
Symptom: SHAP explanations returned unusable all-zero contributions.
Diagnosis: the BankChurn StackingClassifier pipeline was not compatible with the initial TreeExplainer path.
Fix: use KernelExplainer through a predict-proba wrapper in the original feature space, so explanations match the served model contract.
Autoscaling
HPA scale-down fixed¶
Symptom: pods stayed overprovisioned after traffic dropped.
Diagnosis: memory was a misleading HPA signal because ML pods keep a fixed model memory footprint even when request volume falls.
Fix: remove memory-based scaling and use CPU-only HPA, reducing replicas from 3 to 1 in 8 minutes.
Quick Technical Signal¶
System scope
Three ML services beyond notebooks¶
Churn prediction, financial sentiment analysis and taxi demand forecasting with APIs, tests, packaging and documentation.
MLOps fundamentals
Serving, tracking and deployment paths¶
FastAPI, Docker, Kubernetes manifests, MLflow patterns, CI/CD workflows and cloud deployment evidence.
Reliability habits
Measured failures, not just demos¶
Load-test debugging, SHAP troubleshooting, HPA correction, leakage checks and architecture decisions with trade-offs.
Business judgment
Cost and scope are documented¶
The portfolio separates active assets from paused cloud runtime and explains cost-control decisions honestly.
Visual Evidence Shortcuts¶
Serving path
Live ML predictions¶
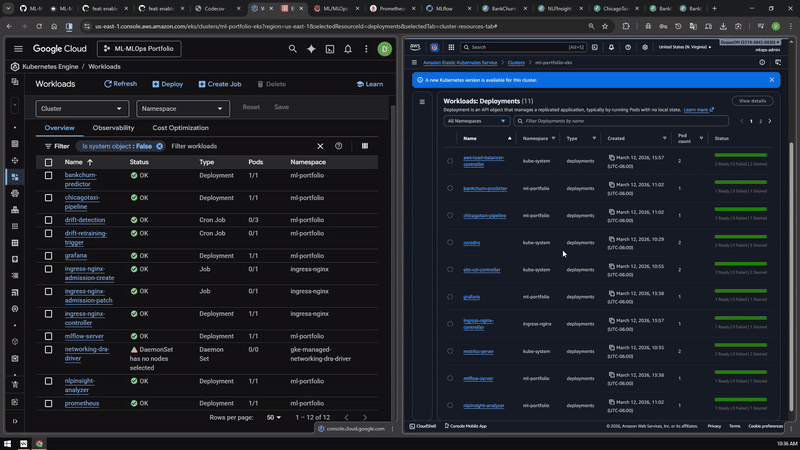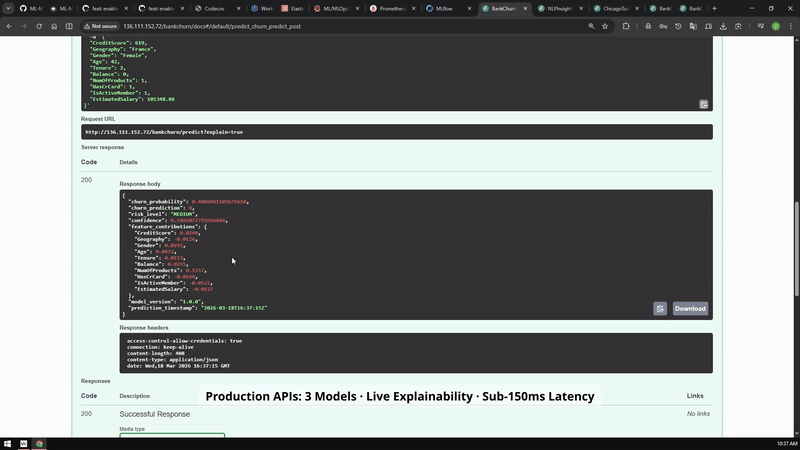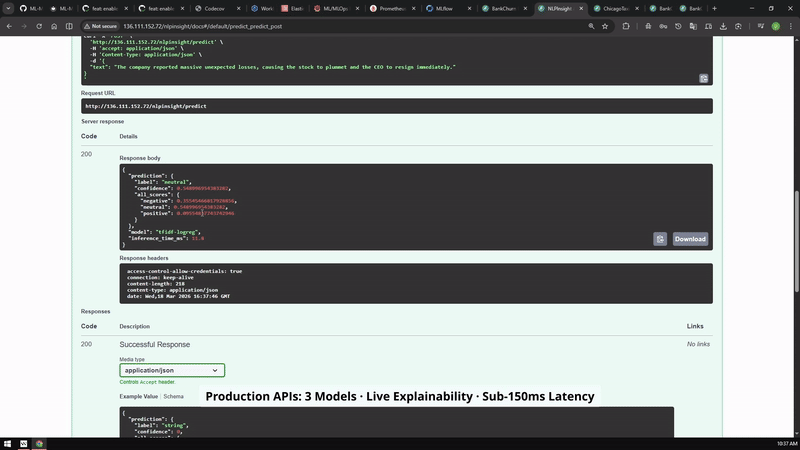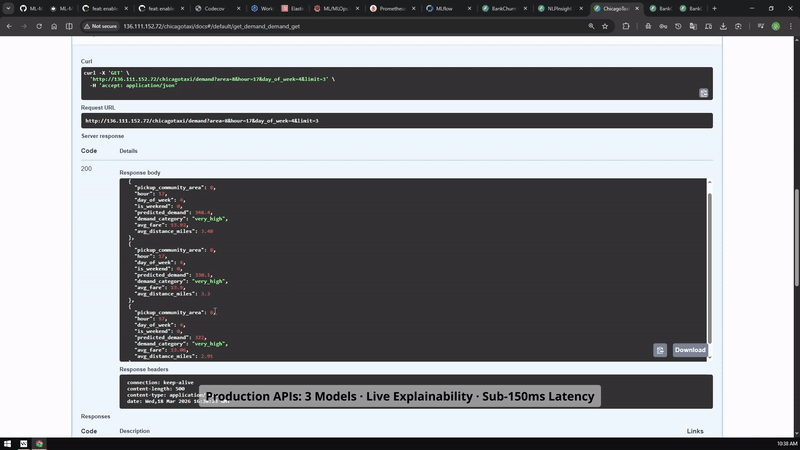
FastAPI prediction paths for the portfolio services, shown as a short visual review instead of another long code block.
Observability path
Monitoring under load¶
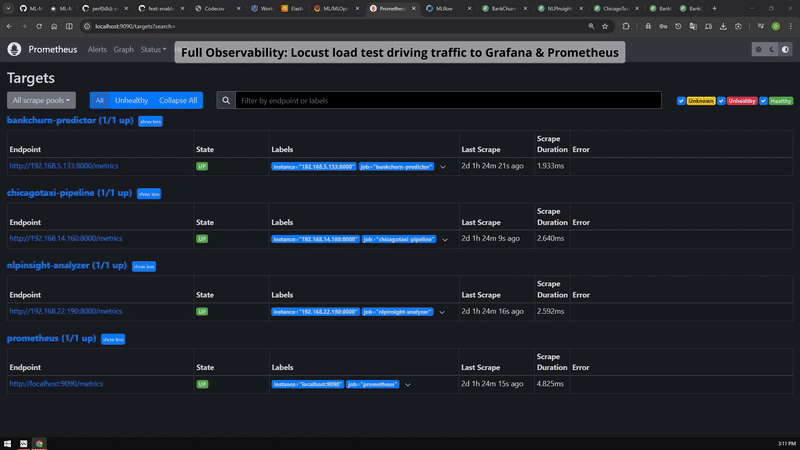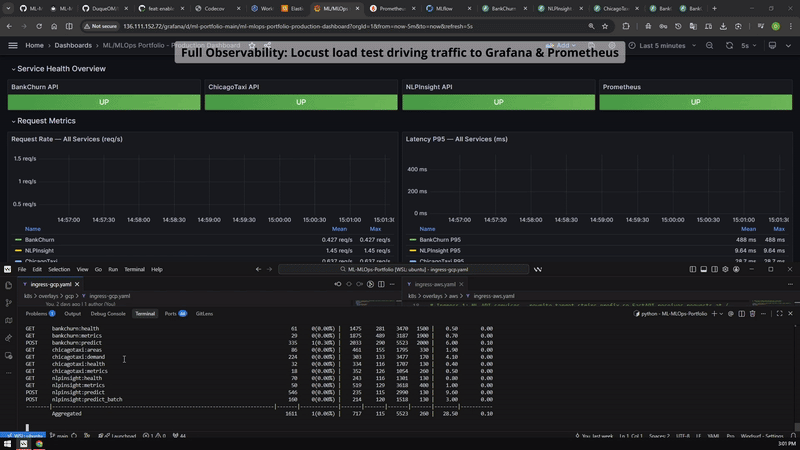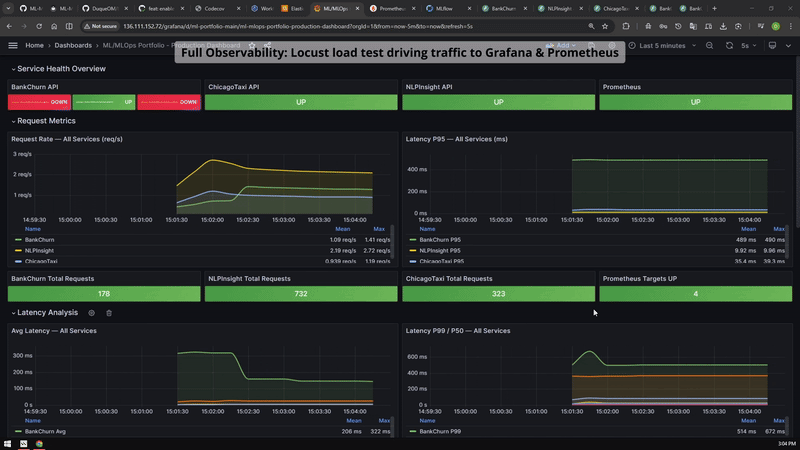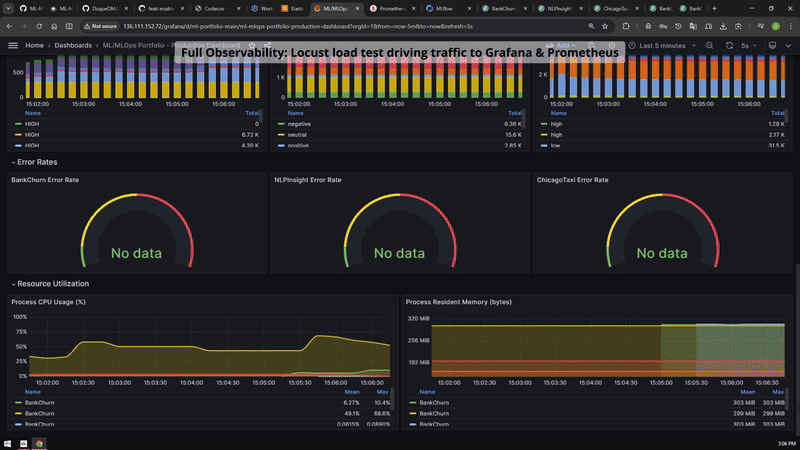
Grafana, Prometheus, Locust and MLflow evidence grouped for reviewers who want runtime behavior, not only architecture claims.
Cloud path
GKE and EKS parity¶
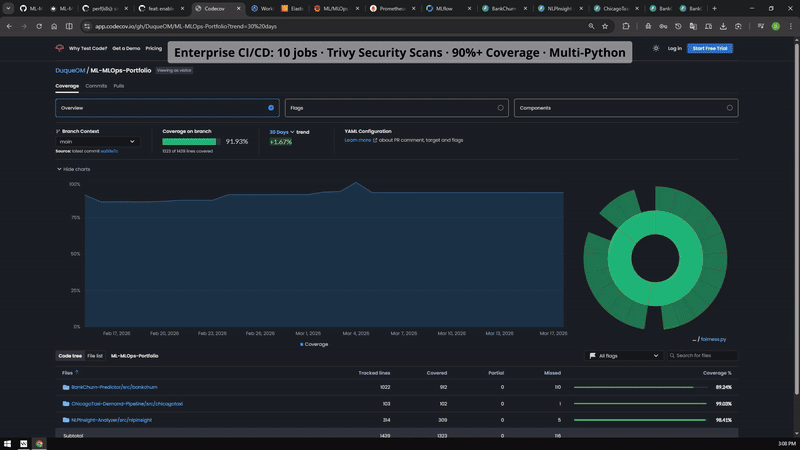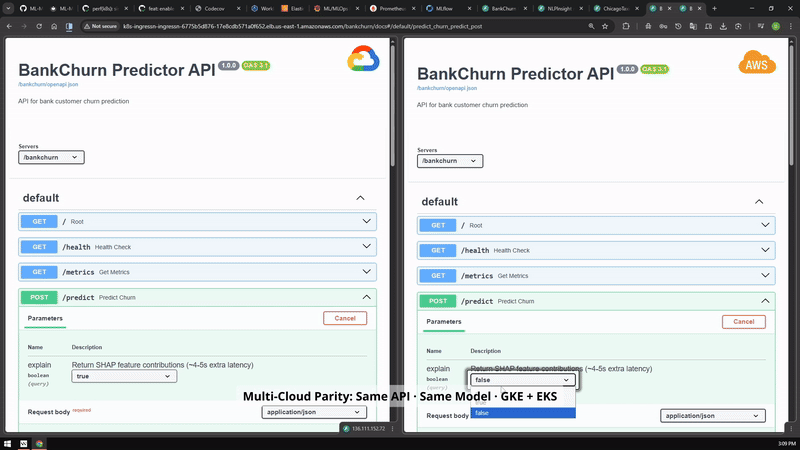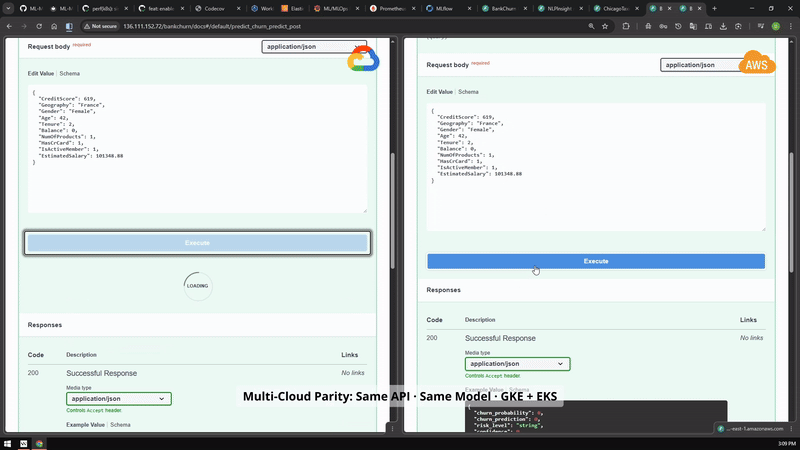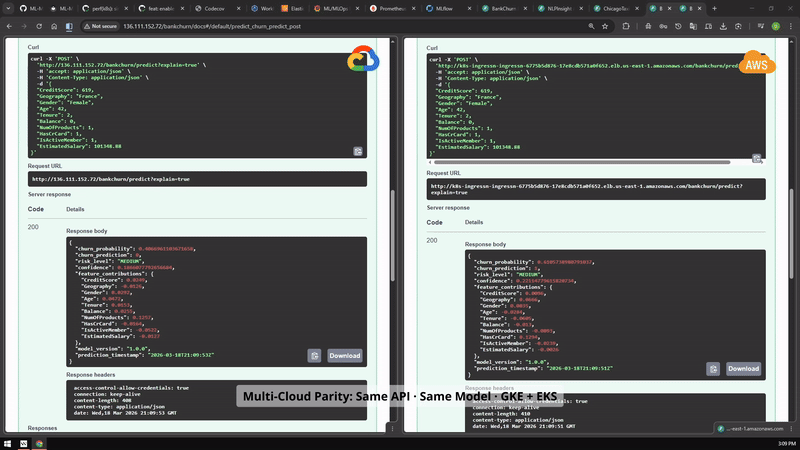
Side-by-side cloud evidence showing that the portfolio was exercised across Google Cloud and AWS Kubernetes environments.
Green Checks And Runtime Evidence¶
CI proof
GitHub Actions completed¶
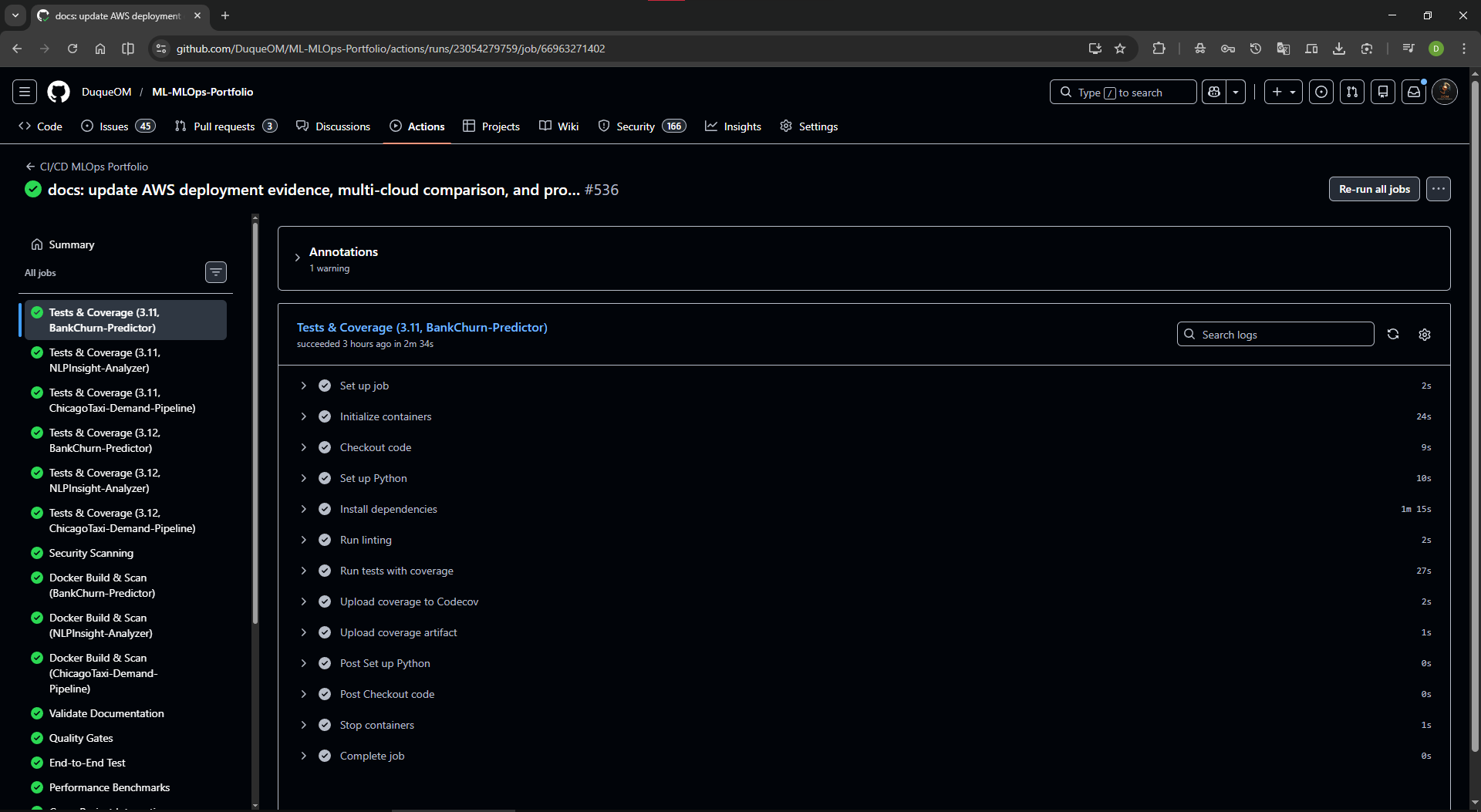
Visible green checks reduce the time a technical reviewer spends wondering whether the 395+ tests are only a claim.
Smoke proof
API health checks passed¶
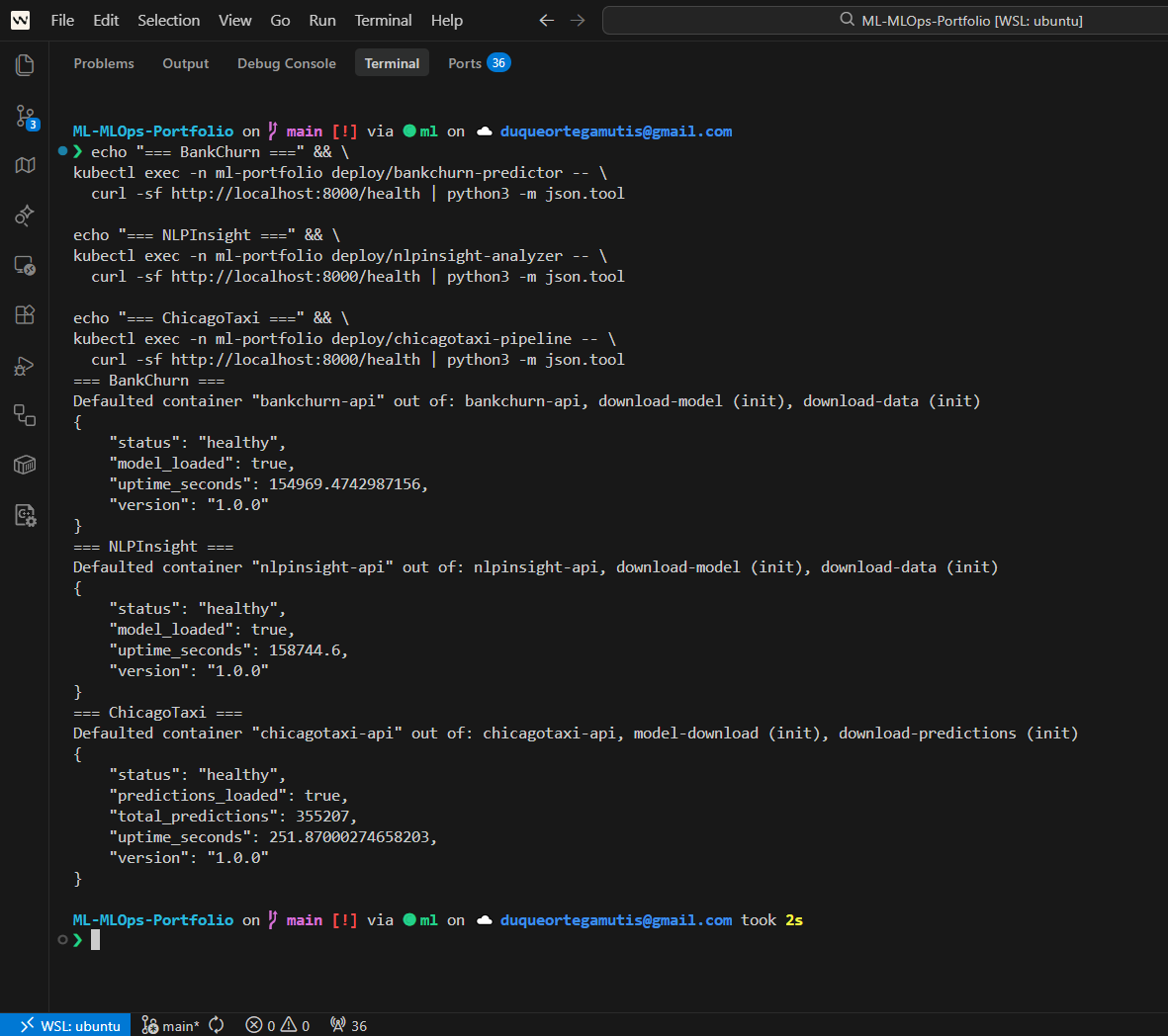
Health-check screenshots show that the APIs were exercised as running services, not only described in documentation.
Model lifecycle
MLflow experiment tracking¶
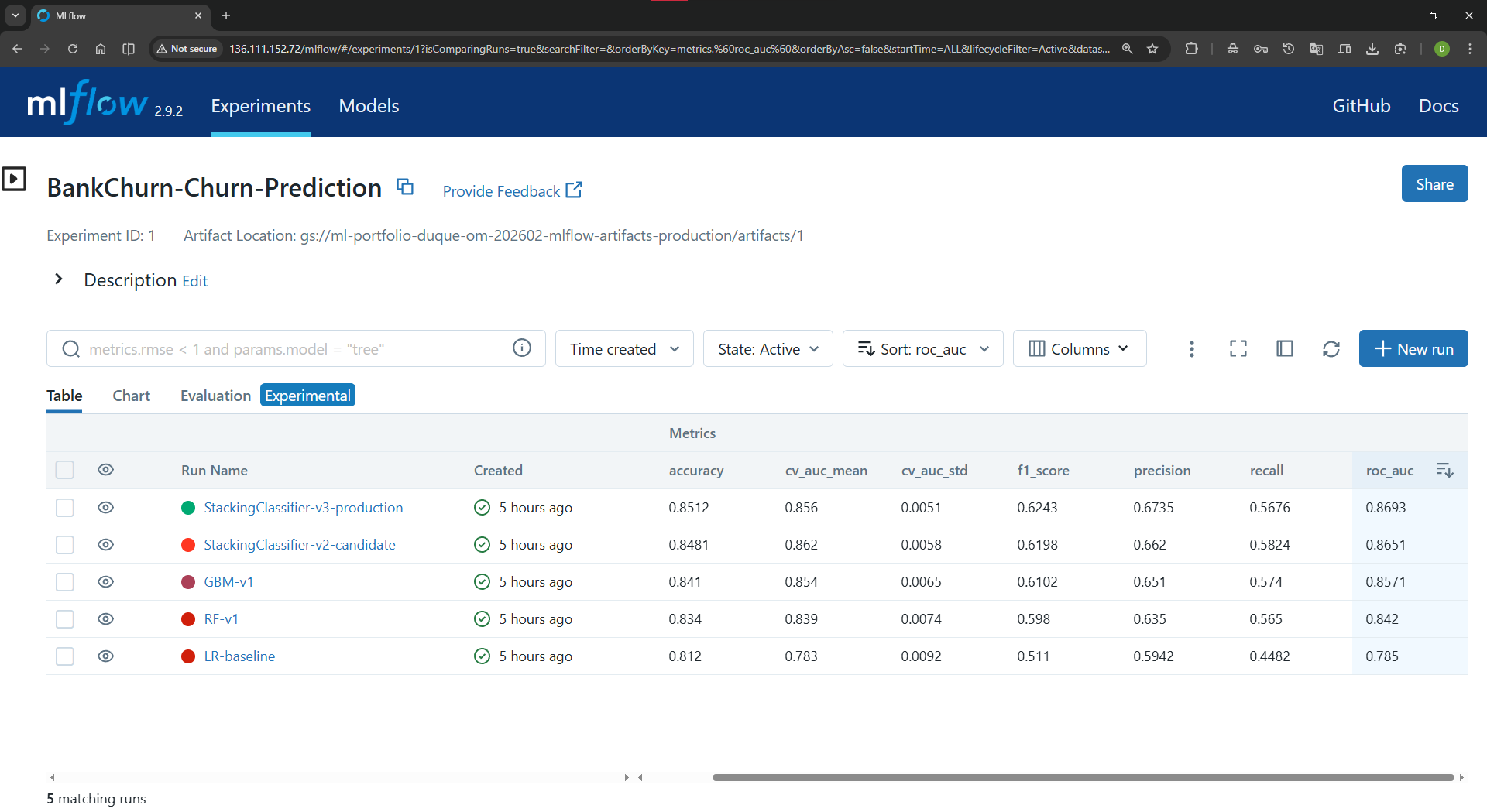
MLflow evidence makes model tracking tangible for reviewers who want to see experiment and model registry habits.
Observability
Grafana and load testing¶
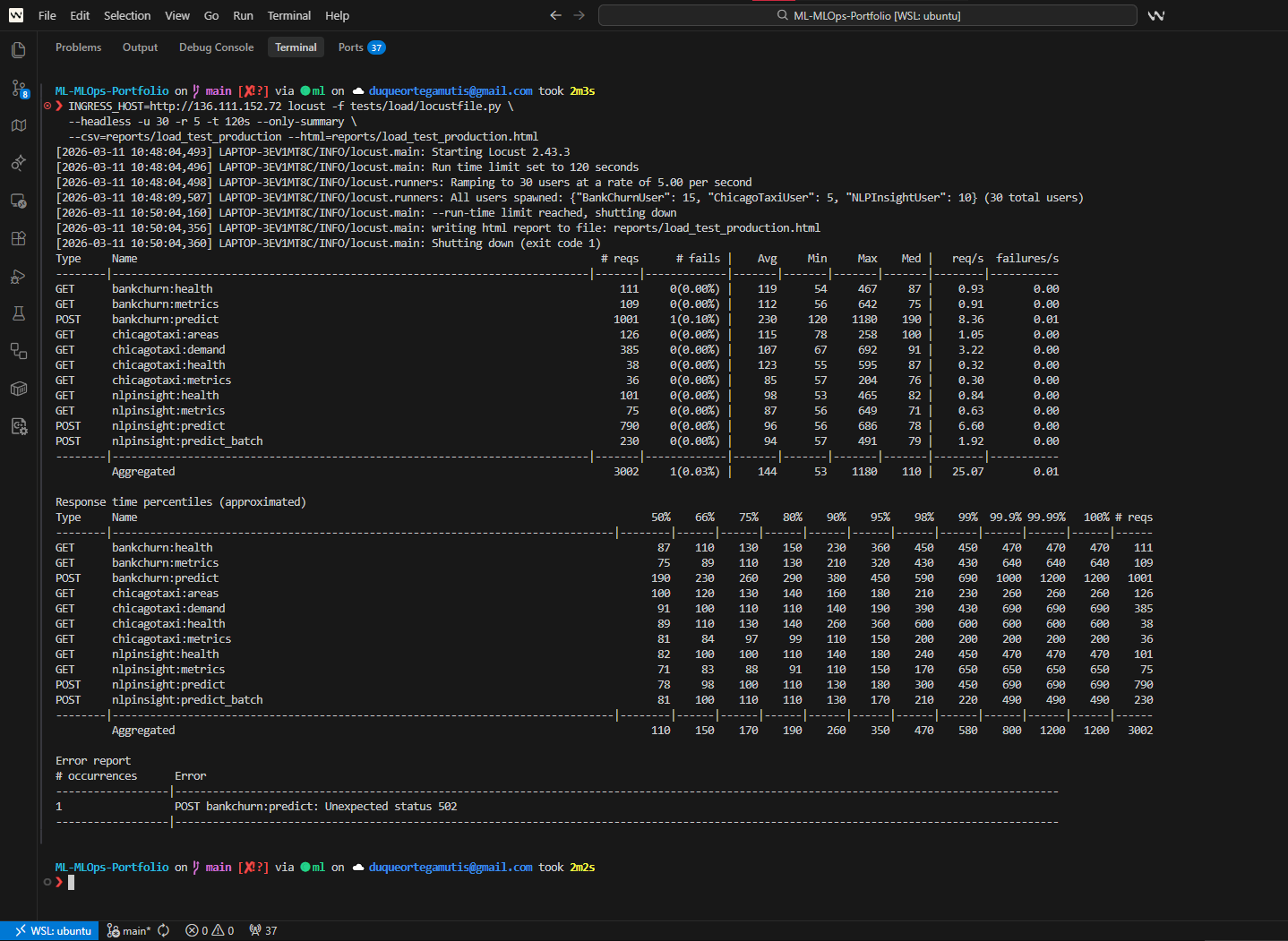
The load-test evidence connects observability claims to measured runtime behavior.
Choose A Review Path¶
3-minute review
Recruiter or first screen¶
Confirm the role fit, current status and what the portfolio is meant to show.
10-minute review
Hiring manager overview¶
Understand the three services, the reusable template and the strongest technical signals without reading the whole archive.
30-minute review
Technical deep dive¶
Open architecture, deployment, operations, model and API documentation in a grouped index instead of a long sidebar.
Key Engineering Decisions¶
Serving
One worker per pod plus executor¶
Kubernetes handles horizontal scaling; the API avoids
uvicorn --workers N inside one pod and keeps the event loop free by
offloading CPU-bound inference work to asyncio.run_in_executor()
and ThreadPoolExecutor.
Cost control
Cloud evidence, not always-on waste¶
The portfolio preserves deployment proof while pausing live clusters when the monthly cost is not justified for a public showcase.
Template extraction
Lessons became guardrails¶
The reusable template turns repeated failure modes into documented defaults, rules and reviewable workflows.
Evidence Highlights¶
Serving
FastAPI inference paths¶
Health checks, metrics endpoints, Swagger docs, Docker builds and API smoke tests make models callable and reviewable.
Cloud
GKE and EKS evidence¶
Kubernetes manifests, Terraform examples, screenshots and CLI evidence preserve the deployment story while runtime is paused for cost.
Operations
Monitoring and runbooks¶
Prometheus, Grafana, MLflow, load tests and troubleshooting notes show how the system would be operated, not only trained.
Deep Archive¶
Projects overview¶
The three ML systems and their main results.
BankChurn debugging deep dive¶
The full failure story: symptoms, hypotheses, root cause, fix, validation and template lesson.
Production template¶
The reusable MLOps project extracted from portfolio lessons.
Deep dive index¶
Grouped technical archive for architecture, deployment, operations, models and API references.
Portfolio status¶
What is active now, what is paused, and how to reactivate a live demo.